Game AI Part 2: Problem Spaces
This is the second part in an series of posts on Game AI. The first post can be found here
When building AI agents that solve complex problems or play games, it helps to consider the problem in this way:
- Consider the starting conditions of the puzzle or game as an Initial State
- Naturally, your goal is to get the game in a certain state (or any such state that satisfies certain conditions). We’ll call these Winning States
- Now consider a wide open space, where every point represents a game state. (You can also see this as a maze of states). We’ll call this the Problem space
- So now solving the problem equates getting from the initial state to a winning state. Sometimes this will require you to FIND the winning state, and sometimes you’d know the exact winning state, but you’d have to figure out the path from an initial state to the winning state. This process is called the Search
An example of a situation where you have to find the path from initial to winning state, where you know the winning state, is the Rubik’s cube. Every state of the cube represents a point in the problem space. You know exactly which state is called the winning state. So the question how to get there from a given initial state?
From any state of the Rubik’s cube, you can go to many other states of the cube depending on what rotation you perform. What should be noted here is that you can’t go to any state from a state, instead specific states can lead to specific states. So this can be visualized as a maze of states. Something similar to this:
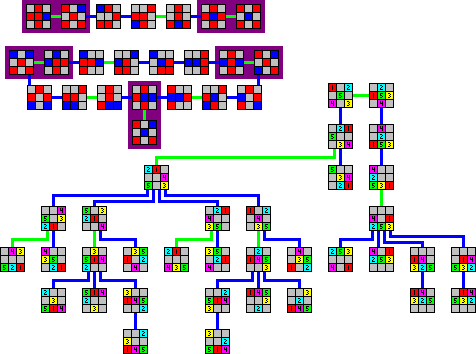
Now obviously, Rubik’s cube has a very complex Problem Space, but what we learn from representing this as a maze, is that now writing an AI agent that can solve the Rubik’s cube is equivalent to writing an AI that can solve a maze. We just need to give it the right maze to solve. So first, let’s consider how to solve a maze. Consider the following maze:

Now instead of considering every point in the maze as a state, let’s simplify things by only consider the ones that present an outcome, or require a decision, i.e:
- The Forks in the roads
- The Dead Ends
- The Exit.

So now you can see there are states that lead to multiple states (forks), and there are those that lead to no new state (dead ends). So we reconstruct this as a tree with the starting position as the root, the dead ends, and exit as leaves.

So to solve the maze, we need to traverse this tree and find a path from root to the leaf marked “Exit”. Assuming the maze has no cycles, one of the simplest ways to do this would be a recursive function (let’s call it “explore”) as follows:
explore ( node n):
- If n is the Exit, add n to solution stack and return “true” or “win”
- else if n is a dead end (no child nodes, and is not an Exit) then return “false” of “fail”
- else (n has child nodes) then for each child node m, explore(m)
- if any child node returns a true/win , then add n to solution stack and return true/win.
We mentioned a solution stack in the above algorithm. This would be a stack data structure that holds a trail of nodes that represent the solution path. We use a stack because we enter the nodes in reverse (pushing to the stack), and then when we want to see the solution, we read them in reverse-order of entry (popping the stack).
Now what this recursive function will do is try each possible path until it finds the exit. If it runs into a dead end, it goes back until it finds a fork that leads to an unexplored path. This going back is called back-tracking. The process of exploring each path till you reach its end, is called depth-first traversal.
The above problem was an example of scenarios where the solution is a path from an initial state to a winning state. As we mentioned before, there are also problems which just require you to find a winning state, irrespective of path. The states in these problem spaces are usually not connected like in the maze. So there aren’t any restrictions on how to get from a state to another. This means that they can’t be directly transformed into a tree.
One such problem is the Eight Queen’s Problem. The object of the game is to place 8 Queens on a chessboard such that they do not attack each other. Now if we think of every arrangement of the queens as a state then the Problem Space will have roughly 648 = 281,474,976,710,656 states (64 blocks where each of the 8 Queens can be placed). This is a considerably large Problem Space.
If we model the problem space this way, this means we have 8 variables (one for each queen’s position) and each of them can have 64 possible values. Now we can reduce this Problem Space considerably if we simply account for the fact that no two queens can be in the same column. So each column will have exactly one queen. So another way to model the Problem Space would be to let the 8 variables represent the row of each Queen (they are already spread across the columns). So that leaves us with 8 variables each of which can have 8 possible values. Thus there are now 88 = 16,777,216 possible states. This is a much smaller Problem Space, but still pretty large.
So how do we search through these 16,777,216 states? Since these states are not exactly interconnected, we don’t have a tree of sorts, to traverse. Now if you notice, until now, we have been considering placing all Queens at once, and then calling it a state. Another way to approach the problem is to place the Queen’s one at a time, for example starting from the left most column and then moving rightwards. After each placement, all next possible placements can be child nodes of that placement. So we can form a tree with empty board as root node, all placements of first queen will be its child nodes, and so on.
We can even further simplify the Problem Space if we only consider legal placements. For example, consider placing the first queen in the middle row:

Now this will block these places on the board for other queens:

So We have 5 possible places in the second column. And after placing the 2nd Queen, we’ll only have 3 places in the 3rd column:

So this reduces the problem spaces a lot more, and each node will have relatively fewer child nodes, thus the traversal should be quicker.